Railsでの検索機能にgroonga-client-railsを使う(前編)
今日の日記はGroonga Advent Calendar 2016の18日目です。
今日はRailsアプリケーションに検索機能を付けるのに、groonga-client-rails gemを使う方法を、サンプルアプリケーションを作りながら紹介したいと思います。長くなったので……というか、準備と書く時間の見積もりを誤ったので、前後編に分けます。前編の今日はインストールからRailsのモデルと検索機能を結び付ける(言い回しが分かりにくいと思いますがあとで分かります)まで紹介し、後編では検索用のUIを作ろうと思います。
以下の環境で動作確認をしています。
- OS … OS X El Capitan 10.11.6
- Ruby … 2.3.3
- Groonga … 6.1.1
- Ruby on Rails … 5.0.0.1
- groonga-client-rails … 0.9.4
目次
groonga-client-railsとは
groonga-client-railsは、Ruby on Railsに検索用の機能を提供するgemです。バックエンドの検索エンジンにGroongaを使っています。以前、RailsにGroongaの検索機能を提供するgemとしてActiveGroongaを紹介しましたが(RailsでActiveGroongaを使う)、groonga-client-railsはこれとは別アプローチのgemです。
ActiveGroonga(が内部で使っているRroonga)はローカルのファイルシステムにGroongaのデータベースを作成し、そこにC API経由でアクセスします。このため、インストール時にCのコンパイルが走り、RailsサーバーとGroongaデータベースは同じマシン上に存在する必要がありました。スケールアウトさせる際にはGroongaデータベースの同期が課題にもなります。
groonga-client-railsが使うGroongaはリモートサーバーです。GroongaはC API経由でアクセスするほかに、HTTPサーバーとして動作し、HTTPクライアントでアクセスしてデータの投入と検索を行うこともできます(GQTPというGroonga独自のプロトコルも使えます)。この用途に向けたgroonga-clientというgemがあり、それをRailsで使いやすくしたのがgroonga-client-railsです。
groonga-client-railsでは、ActiveJobのXxxJob、CarrierWaveのXxxUploaderのようなXxxSearcherというサーチャークラスを作って検索エンジンへのアクセスを抽象化します。サーチャーの作り方は後述しますが、モデルクラス一つと対応付けられ、モデルの(RDBMSやMongoDBなどへの)保存・更新・削除とGroongaの対応テーブルとの同期を取ったり、対応テーブルからの検索用APIを提供したりします。うまくインターフェイスを揃えればElsticsearchとかも同じクラスで扱えるかも?
サンプルアプリケーションについて
サンプルとして、SQLite3のpostsテーブルにメモを入れたり読んだりするだけの簡単なRailsアプリケーションを使って、groonga-client-railsを導入していきます。
ソースコードはこちら: KitaitiMakoto/groonga-client-rails-sample
上で「groonga-client-railsが使うGroongaはリモートサーバーです。」と書きましたが、今回はGroongaもRailsも同じローカルマシンで動かして、127.0.0.1でHTTPでアクセスさせようと思います。
なお、アプリケーション作成においてはgroonga-client-railsのテストディレクトリーを大いに参考しました。ほぼまんまです。
インストール
Groongaのインストールは公式サイトのドキュメント(2. インストール)を見ながらやってください。日本語を扱うと思うので、MeCabトークナイザーもインストールしておくといいと思います(これもドキュメントに記載があります)。
OS XであればHomebrewでインストールできます:
% brew install groonga --with-mecab
% brew install mecab-ipadic
groonga-client-railsのインストールは、いつも通りGemfileに
gem 'groonga-client-rails'
と書いて
% bundle install --path=vendor/bundle
です。
軽く確認しておきましょう。
% ./bin/rails --help | grep groonga
groonga:sync # Synchronize Groonga database with model data
タスクが追加されていますね。後で実際に使ってみます。
基本機能の作成
postsを読み書きするための土台を作ります。
% ./bin/rails generate scaffold post title:string body:text
Expected string default value for '--jbuilder'; got true (boolean)
invoke active_record
create db/migrate/20161217142208_create_posts.rb
create app/models/post.rb
invoke test_unit
create test/models/post_test.rb
create test/fixtures/posts.yml
invoke resource_route
route resources :posts
invoke scaffold_controller
create app/controllers/posts_controller.rb
invoke erb
create app/views/posts
create app/views/posts/index.html.erb
create app/views/posts/edit.html.erb
create app/views/posts/show.html.erb
create app/views/posts/new.html.erb
create app/views/posts/_form.html.erb
invoke test_unit
create test/controllers/posts_controller_test.rb
invoke helper
create app/helpers/posts_helper.rb
invoke test_unit
invoke jbuilder
create app/views/posts/index.json.jbuilder
create app/views/posts/show.json.jbuilder
create app/views/posts/_post.json.jbuilder
invoke assets
invoke coffee
create app/assets/javascripts/posts.coffee
invoke scss
create app/assets/stylesheets/posts.scss
invoke scss
create app/assets/stylesheets/scaffolds.scss
Generate posts scaffold
追加されたファイルを見てみます。
% git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: config/routes.rb
Untracked files:
(use "git add <file>..." to include in what will be committed)
app/assets/javascripts/posts.coffee
app/assets/stylesheets/posts.scss
app/assets/stylesheets/scaffolds.scss
app/controllers/posts_controller.rb
app/helpers/posts_helper.rb
app/models/post.rb
app/views/posts/
config/groonga_client.yml
db/migrate/
test/controllers/posts_controller_test.rb
test/fixtures/posts.yml
test/models/post_test.rb
no changes added to commit (use "git add" and/or "git commit -a")
config/groonga_client.ymlというファイルが出来ていますね(ジェネレーターのアウトプットには出て来ないので、見逃しそうでした)。中身はこうです。
default: &default
protocol: http
# protocol: https
host: 127.0.0.1
port: 10041
# user: alice
# password: secret
read_timeout: -1
# read_timeout: 3
backend: synchronous
development:
<<: *default
test:
<<: *default
port: 20041
production:
<<: *default
host: 127.0.0.1
read_timeout: 10
何となく分かると思います。10041番ポートは、GroongaのHTTPサーバーを起動する時のデフォルトポートです。
Groongaについては一先ず置いておいて、RDB(SQLite3)の作成とマイグレーションをします。
% ./bin/rails db:migrate
== 20161217142208 CreatePosts: migrating ======================================
-- create_table(:posts)
-> 0.0014s
== 20161217142208 CreatePosts: migrated (0.0015s) =============================
http://localhost:3000/posts にアクセスすると、アプリケーションが動いているのが確認できると思います。

検索機能との結び付け
Groongaの起動
サンプルアプリと検索機能を結び付ける前に、まずGroongaを起動しておきましょう。
% groonga --protocol http -s -n db/groonga.db
-nは「新しくデータベースを作る」というオプションで、Groongaデータベースがまだない時に一度だけ指定します。二度目以降は不要なので
% groonga --protocol http -s db/groonga.db
として起動します。
終了させるにはCtrl+CでSIGINTを送ります(デーモンモードなどについてはドキュメントを見てください)。
db/groonga.db は指定したパス(及びそれをプリフィクスとしたパス)にデータベースファイルを作成するという意味です。Railsのdbディレクトリーを指定しています。
サーバーモードのGroongaは、検索用のAPIの他に人間用の管理インターフェイスも持っています。http://localhost:10041/ にアクセスしてみてください。

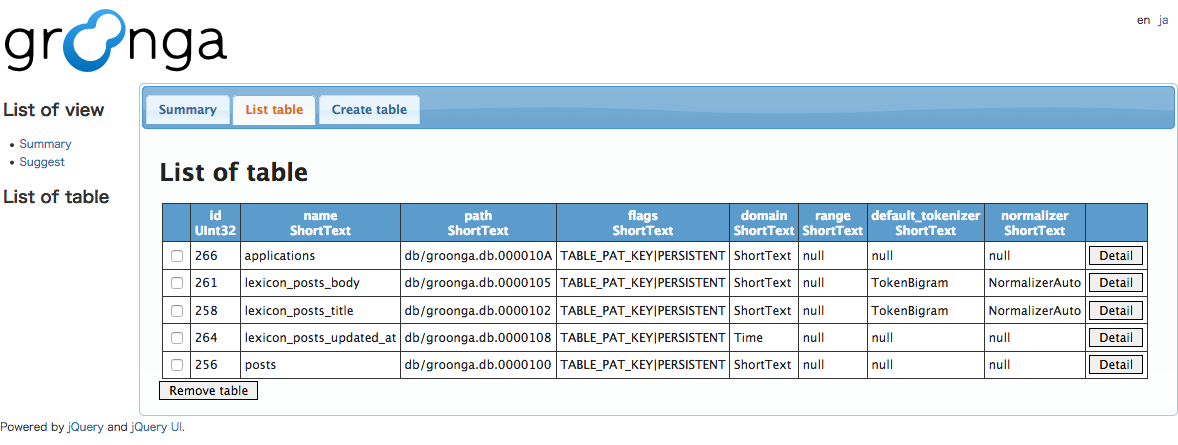
まだテーブルの作成すらしていないので、左側の「List of table」欄には何もありません。
サーチャークラスの作成
RailsアプリとGroongaとの結び付けをするサーチャークラスを作成します。サーチャークラスはモデルクラス一つにつき一つまで作成することができます1。不要なモデルについては、当然作る必要はありません。
ここではPostモデルしかないのでこれに対応するクラスを作成するのですが、他の種類のクラスの例に漏れず、まずapp/searchers/application_searcher.rbファイルにApplicationSearcherクラスを作りましょう。
class ApplicationSearcher < Groonga::Client::Searcher
end
次にPostsSearcherクラスをapp/searchers/posts_searcher.rbに作ります。
class PostsSearcher < ApplicationSearcher
schema.column :title, {
type: "ShortText",
index: true,
index_type: :full_text_search
}
schema.column :body, {
type: "Text",
index: true,
index_type: :full_text_search
}
schema.column :updated_at, {
type: "Time",
index: true
}
end
何となく分かると思いますが、schema.columnメソッドの第一引数(:title、:body、:updated_at)は、Groonga上の検索条件や結果に使うカラムです(Groongaもカラムとレコードでデータを管理する、テーブル型のデータベースです)。このカラムに検索語が含まれているかとか、範囲内に収まっているかとかで検索することになります。これからGroongaのテーブル上に作成するカラム名なので、RDBMSのカラム名とは違っていてもいいのですが、同じにしておく方が分かりやすいでしょう。
第二引数でそのカラムの性質を定義します。typeはGroongaのデータ型をします。大体分かると思うので、このまま進めましょう。実際に使う時には公式ドキュメント(7.4. データ型)を参照してください。
indexはインデックスを張るかどうかで、RDBMSと同様、張れば検索やソートが速くなるし、張らなければストレージやメモリーを節約できます。検索エンジンを導入するという時点で、殆どのカラムにtrueを指定することになると思います。「検索結果表示には使うけど、検索条件には使わない」という付随的な情報のカラムでだけfalseにしておきます。
index_typeは、全文検索に使うカラムでだけ:full_text_searchを指定します。それ以外の場合は無くて構いません。例えば:updated_at(日時)は範囲指定に使うことはあっても全文検索には使わないので、ここでも指定されていません。
他にvectorをtrueかfalseで指定することができるようで、Groongaのベクター型に対応すると思われます。ベクター型についても詳細はドキュメントを参照してください。「投稿に複数タグを付けられる場合の、タグ」など、配列のように複数の値が入るカラムをベクターにします(この日記のタグもベクターとしてGroonga上のカラムにしています)。
本来、Groongaのテーブルではもっと細かなチューニングができますが、groonga-client-railsでは(今の所)ライブラリーのおすすめ設定を使うことになります。
モデルクラスとサーチャークラスとの結び付け
次に、Postモデルに設定を書いてPostsSearcherと結び付けます。
class Post < ApplicationRecord
searcher = PostsSearcher.source(self)
searcher.title = :title
searcher.body = ->(model) {
model.body.gsub(/<.*?>/, "")
}
searcher.updated_at = true
end
この設定をすることでモデルクラスのafter_create、after_update、after_destroyフックにコールバックが登録されて、リモートのGroongaサーバーと同期が取れるようになります(なので、これらのフックさえあればActiveRecord以外のクラスでも結び付けられます)。
ここでsearcherの属性ライター(title=、body=、updated_at=)は、Groongaデータベース側のカラム名を意味しています。右辺には
SymbolTrueClassNilClassProcなど#callメソッドを持つオブジェクト
のいずれかを指定できます。
searcher.updated_at = true
のようにTrueClassの場合は、モデルクラス(Post、postsテーブル)の、左辺と同名の属性・カラム(updated_at)の値を取得して、その値をGroongaデータベースと同期します。なので実は
searcher.title = :title
も
searcher.title = true
で構いません。
Symbolは、「RDBMSのカラム名とGroongaデータベースでのカラム名が違う」といった場合に活きます。
Procの場合は見れば分かると思います。#callの戻り値がGroongaデータベースの該当カラムに挿入されます。ここではHTMLタグっぽい文字列を削除しています。
最後にnilの場合は、そのカラムはGroongaデータベースに入りません。「始めは使っていたけど後から使わなくなったカラム」なんかで使うんでしょうかね。
データの同期
さて、これでRDBMS(SQLite3)とGroongaとでデータの同期が取れるようになりました—これからのデータについては。
この時点ではRailsを再起動したりしても既存のデータが同期されません。既存データを一括同期するためには、groonga-client-railsが提供するRakeタスクを使います。
% ./bin/rails groonga:sync
これを実行してGroonga管理画面(http://localhost:10041/)にアクセスし「List table」をクリックすると、postsなど今定義したテーブルが出来ているのが分かります。
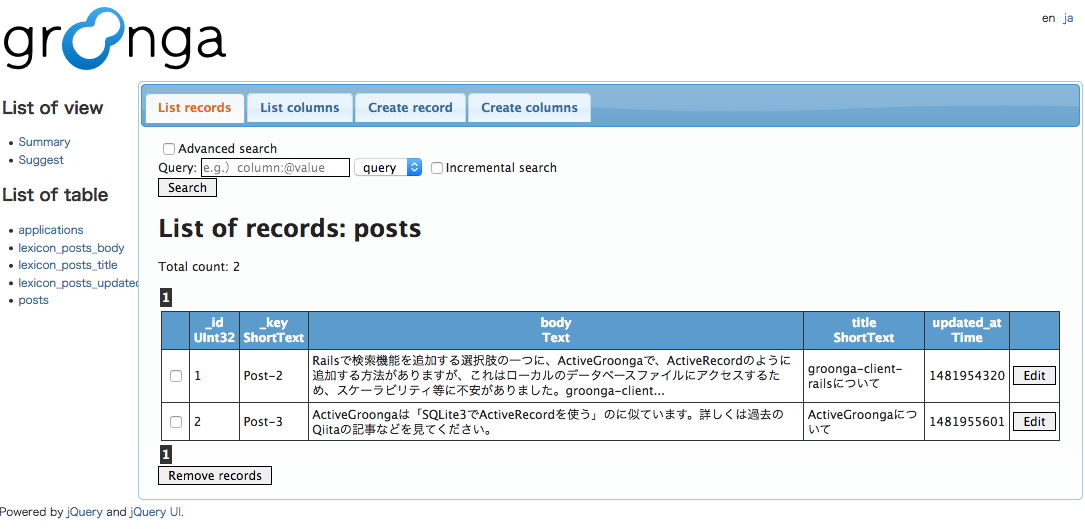
postsの「Detail」ボタンを押すと、既存のレコードが同期されているのが分かります。
通常のモデルの操作でデータが同期されるのも見ておきましょう。Railsのscaffoldで出来たUIで、データを追加します。

管理画面を見ると、Groongaにも対応するデータが入っています。
おまけ - 検索して遊ぶ
今日はここまで。次回は検索用のUIを導入しようと思います。
が、効果を実感しにくい、地道な作業ばかりだったので、少しだけ遊んでみましょう。今日の作業分で、コンソールで検索ができるようになっています。
% ./bin/rails console
検索ではPostsSearcher#searchメソッドから開始して(whereのように)検索クエリーを組み立て、result_setでGroongaへアクセスして結果を取得します。
searcher = PostsSearcher.new
searcher.search.result_set
=> #<Groonga::Client::Searcher::Select::ResultSet:0x007fd7c4b0f7e0 @response=#<Groonga::Client::Response::Select:0x007fd7c4b1d318 @command=#<Groonga::Command::Select:0x007fd7c4adf388 @command_name="select", @arguments={:table=>"posts", :match_columns=>"title, body"}, @original_format=nil, @original_source=nil, @path_prefix="/d/", @slices={}, @drilldowns=[], @labeled_drilldowns={}>, @header=[0, 1481988639.462895, 0.0001811981201171875], @body=[[[2], [["_id", "UInt32"], ["_key", "ShortText"], ["body", "Text"], ["title", "ShortText"], ["updated_at", "Time"]], [1, "Post-2", "Railsで検索機能を追加する選択肢の一つに、ActiveGroongaで、ActiveRecordのように追加する方法がありますが、これはローカルのデータベースファイルにアクセスするため、スケーラビリティ等に不安がありました。groonga-client-railsなら、リモートのGroongaサーバーにHTTPやGQTPでアクセスできるので、スケーラビリティや保守性をDBやアプリケーションサーバーと別々に考えることができます。", "groonga-client-railsについて", 1481954320.0], [2, "Post-3", "ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。", "ActiveGroongaについて", 1481955601.0]]], @n_hits=2, @records=[{"_id"=>1, "_key"=>"Post-2", "body"=>"Railsで検索機能を追加する選択肢の一つに、ActiveGroongaで、ActiveRecordのように追加する方法がありますが、これはローカルのデータベースファイルにアクセスするため、スケーラビリティ等に不安がありました。groonga-client-railsなら、リモートのGroongaサーバーにHTTPやGQTPでアクセスできるので、スケーラビリティや保守性をDBやアプリケーションサーバーと別々に考えることができます。", "title"=>"groonga-client-railsについて", "updated_at"=>2016-12-17 14:58:40 +0900}, {"_id"=>2, "_key"=>"Post-3", "body"=>"ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。", "title"=>"ActiveGroongaについて", "updated_at"=>2016-12-17 15:20:01 +0900}], @slices={}, @drilldowns=[], @raw="[[0,1481988639.462895,0.0001811981201171875],[[[2],[[\"_id\",\"UInt32\"],[\"_key\",\"ShortText\"],[\"body\",\"Text\"],[\"title\",\"ShortText\"],[\"updated_at\",\"Time\"]],[1,\"Post-2\",\"Railsで検索機能を追加する選択肢の一つに、ActiveGroongaで、ActiveRecordのように追加する方法がありますが、これはローカルのデータベースファイルにアクセスするため、スケーラビリティ等に不安がありました。groonga-client-railsなら、リモートのGroongaサーバーにHTTPやGQTPでアクセスできるので、スケーラビリティや保守性をDBやアプリケーションサーバーと別々に考えることができます。\",\"groonga-client-railsについて\",1481954320.0],[2,\"Post-3\",\"ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。\",\"ActiveGroongaについて\",1481955601.0]]]]">>
searcher.search.query('Qiita').result_set
=> #<Groonga::Client::Searcher::Select::ResultSet:0x007fd7c66d14b0 @response=#<Groonga::Client::Response::Select:0x007fd7c66d1f00 @command=#<Groonga::Command::Select:0x007fd7c40cb400 @command_name="select", @arguments={:table=>"posts", :match_columns=>"title, body", :query=>"Qiita"}, @original_format=nil, @original_source=nil, @path_prefix="/d/", @slices={}, @drilldowns=[], @labeled_drilldowns={}>, @header=[0, 1481988733.769218, 0.1913049221038818], @body=[[[1], [["_id", "UInt32"], ["_key", "ShortText"], ["body", "Text"], ["title", "ShortText"], ["updated_at", "Time"]], [2, "Post-3", "ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。", "ActiveGroongaについて", 1481955601.0]]], @n_hits=1, @records=[{"_id"=>2, "_key"=>"Post-3", "body"=>"ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。", "title"=>"ActiveGroongaについて", "updated_at"=>2016-12-17 15:20:01 +0900}], @slices={}, @drilldowns=[], @raw="[[0,1481988733.769218,0.1913049221038818],[[[1],[[\"_id\",\"UInt32\"],[\"_key\",\"ShortText\"],[\"body\",\"Text\"],[\"title\",\"ShortText\"],[\"updated_at\",\"Time\"]],[2,\"Post-3\",\"ActiveGroongaは「SQLite3でActiveRecordを使う」のに似ています。詳しくは過去のQiitaの記事などを見てください。\",\"ActiveGroongaについて\",1481955601.0]]]]">>
後編ではこれを使って検索UIを組み立てます。
追記。
後編を書きました:Railsでの検索機能にgroonga-client-railsを使う(後編)
正確には二つ以上作れますが、あまり意味がないと思います。 ↩




