EPUB書籍に正誤表を反映する(Rubyスクリプトで)、またはEPUBのパッチプログラムの試み
田中哲さんの『APIデザインケーススタディ』を買ったので、前『Dockerエキスパート養成読本』でやったように(Dockerエキスパート養成読本を、ソースコードのシンタックスハイライトしながら読む)ソースコードの部分をシンタックスハイライトしようとしたところで、ただただしさんの「EPUB書籍に正誤表を反映する」という日記を読んだ。本の正誤表を見ながらEPUBファイルの中身を直接書き換えることで、誤りを正した状態で読み始められるようにする、という内容だ。
これは素晴らしい、ぜひ真似しよう、と思って、スクリプトを書いた:
https://gist.github.com/KitaitiMakoto/7b2286b61a0bafcc5926
必要なのは
- 『APIデザインケーススタディ』のEPUBファイル(
path/to/book.epubにあることにする) - Ruby
- 幾つかのRubyGem:
$ gem install nokogiri-xml-range epub-parser epub-maker - Gistにある
reflect-errata-api-design.rbのファイル
で、全て揃ったら
$ ruby reflect-errata-api-design.rb path/to/book.epub
と実行すると正誤表を反映してくれる。

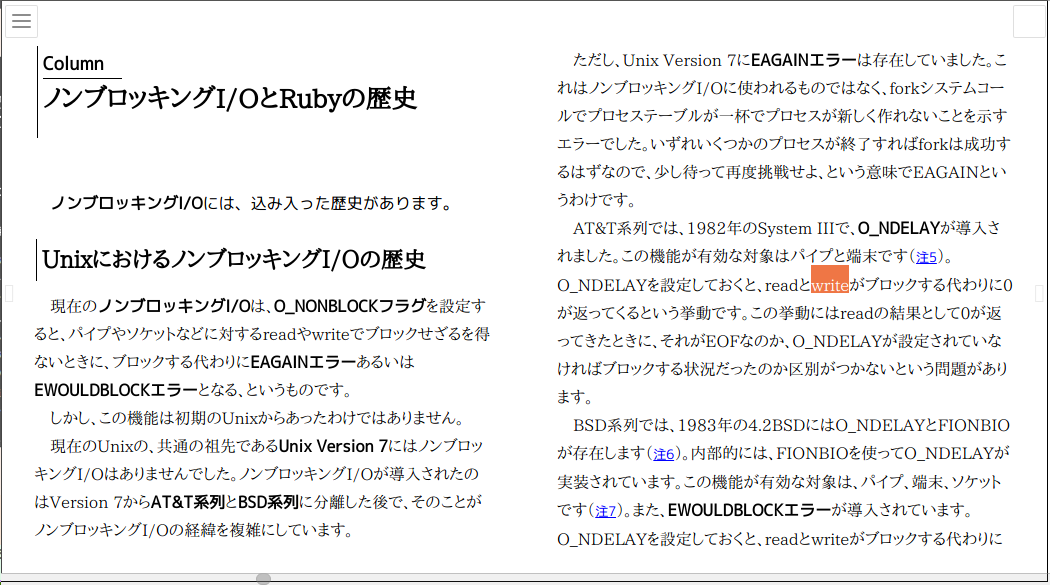 「wirte」だった所が「write」と修正されている
「wirte」だった所が「write」と修正されている大掛かりである。上記の手順だけで充分大掛かりなのに、このスクリプトを書くには数時間を要している。今回程度の数、内容なら、たださんの日記にあるように、エディターを使って手作業で反映させるのが一番手間がないだろう。
ちなみに
正誤表はページ数指定なので、HTMLファイルを特定するのにPDF版を参照してページ数から章番号を突き止めるしかないのがやや面倒
とのことで、EPUBでの対応箇所を探す多分一番簡単な方法は
- EPUBファイルを展開する
$ unzip path/to/book.epub -d api-design grepやThe Silver Searcher(ag)、The Platinum Searcher(pt)で展開したディレクトリーを探す
$ ag wirte api-design
$ ag をを api-design
:
ではなかろうかと思う(検索機能付きのパソコン向けEPUBリーダーってある?)。
使っているgemの紹介
さてこのスクリプト、これまで色々準備してたことのプチ決算な趣があるので、少し自慢話にお付き合い願いたい。動かすのに必要なgemを三つ挙げたが、全て僕が作ったgemで、こんなこともあろうかと準備してきた物々なのである。
EPUB ParserのCFI実装
前からずっとEPUB Parserという、EPUBファイルの中身を調べるgemを作っていた。このgemが扱っているEPUB 3仕様にはEPUB CFIという補足的な仕様がある。「本の中のある一点(一文字)」や「ある場所からある場所まで」といった範囲を指定するための記法を定義した仕様だ。
epubcfi(/6/36!/4/2/16/5,:25,:27)
のようなちょっと目を疑う読みにくさの記法なのでずっと敬遠してきたのだが、ちょうど今回の「EPUBパッチ」のような時に使えるかと、数か月前に重い腰を上げて実装したのだった。
正確にはパッチで終わるのでなく、差分アップデートをやってみたいと思っている。対象もEPUBじゃなくてDOMにしたい、つまりウェブページも対象にしたい。ただ、まずは(要素の省略などが許されているHTMLでなく)必ずXHTMLを使うことになっているEPUBからと思っているし、EPUBでこれができると、Kindleのようなプラットフォームで、本につけたハイライトやメモ書きを保持したまま本の内容をアップデートできるはずだ。電子書籍のいいところに、配信側が気軽にアップデートできることがあるが、そのたびにメモ書きが消えてしまうのは避けたい。また、まんがなんか特にそうだが、不要な所も含めた本全体をアップデートしていると転送料ももったいないしユーザーも長く待たされる。差分アップデートならこれが避けられる。
そんな思惑で実装していたCFIの機能が、今回役に立った。Gistにあるスクリプトの
ERRATA = [
{target: '/6/36!/4/2/16/5,:25,:27', operation: :replace, replace: 'ri'},
{target: '/6/36!/4/2/18/7,:33,:35', operation: :replace, replace: 'ri'},
{target: '/6/46!/4/2/70/6/1,:0,:4', operation: :replace, replace: 'send'},
{target: '/6/52!/4/2/28/1,:61,:62', operation: :remove},
{target: '/6/68!/4/2/44/1:267', operation: :add, add: 'が'},
{target: '/6/98!/4/2/12/9:7', operation: :add, add: '*10'},
{target: '/6/118!/4/2/50/3,:45,:46', operation: :remove}
]
という定数で使っている。targetプロパティのところがそれだ。
カンマで区切られているやつが「範囲」で、区切られていないのが「一点」を表す。削除や差し替えは「どこを」という情報が必要だから範囲を使っているし、文字の追加は不要なので一点を使っている。
このCFI、おもしろい特徴があって、CFI同士、順番をつけることができるのだ。まあ、(始めから終わりまで一次元に続く)本の一点や範囲を示しているんだから、数直線上の点や範囲と同じで、考えてみれば順序が付くのは当たり前なのだが。この順番を、XHTML文書その物は参照せずに決められるところがおもしろい。他に何も見ないでも、
epubcfi(/6/36!/4/2/16/5:25)
と
epubcfi(/6/36!/4/2/18/7:33)
なら前者(epubcfi(/6/36!/4/2/16/5:25))のほうが「先」にあるということが分かる。正誤表適用前に、適用箇所が後ろの方から前の方に並ぶように、正誤表を並び替えているのだが、その時に、この順番の機能を使った(Rubyのsort_byメソッドのブロックから返している)。なぜ後ろから前なのかと言うと、もし前からやってしまうと、適用の結果DOMツリーの構造が変わって、その後の操作の適用対象がずれてしまうことがあるからだ(DOMのNodeSetの中から複数ノードを消すときなんかと同じ)。
これは同じくDOMツリー上の場所を示すのによく使われるCSSセレクターやXPathにはない特徴で、パッチ適用箇所の表現に(渋々ながら)EPUB CFIを採用した理由になっている(CSSセレクターやXPathでも一定の制限を掛けてみんな守るようにすれば順番付けはできる)。
余談だけど、insertじゃなくてadd、deleteじゃなくてremoveといった用語はXML PatchとJSON Patch(日本語訳)から拝借した。
Nokogiri::XML::Range
Nokogiri::XML::Rangeについては以前にも書いた(NokogiriでHTML(XML)内の範囲を操作するgem作った)。DOMツリー上の範囲を扱うgemだ。ウェブブラウザーではJavaScript向けのAPIであるRangeオブジェクトとして見ることができる。
EPUB CFIで正誤表適用箇所を指定できたとしても、そこに対して操作ができなければまるで意味がない。CFIからNokogiri gemで表現されたDOMツリー上の範囲へ変換し、それに対して追加・削除・差し替えを実施するのにNokogiri::XML::Rangeを使っている(長さ0の範囲に対する操作として、追加にも範囲を使っている)。
こう使っている。
range = Nokogiri::XML::Range.new("CPUB CFIから変換した「始点」と「終点」の情報")
## 追加操作 ##
# rangeは追加するべき場所を示している
text_to_insert = Nokogiri::XML::Text.new("追加する文字列", "ドキュメントオブジェクト")
range.insert_node text_to_insert
## 削除操作 ##
# rangeは削除するべき範囲(「をを」の「を」一つとか)を示している
range.delete_contents
## 差し替え操作 ##
# rangeは差し替えるべき範囲(誤字「wirte」の「ir」とか)を示している
range.delete_contents
text_to_replace Nokogiri::XML::Text.new("差し替え後の文字列", "ドキュメントオブジェクト")
range.insert_node text_to_replace
delete_contentsやinsert_contentsがやっていることは実装すると結構めんどうなのだけど、きちんと仕様の存在する挙動なので、gemに切り出しておけば安心して使える。
これも正に「差分アップデートやるなら必要になるはずだな」と思って作ったgemなので、狙い通りに役立って嬉しい。
EPUB Maker
EPUB MakerはEPUB Parserの拡張で、その名の通りEPUBを作成するためのgem……というのは表の顔で、これを作った一番の動機はEPUBのインプレース編集にあった(EPUBを作るならRe:VIEWやgepubなど他のgemのほうがいいと思う)。
冒頭でちょっと触れたDocker本のシンタックスハイライトでも使っているが、EPUBファイルの中身を、Nokogiriを使ったDOM操作などで直接書き換えることができる。
Nokogiri::XML::Rangeで正誤表を適用したあとは、単にEPUB Makerの保存用メソッドを呼べば、それでEPUBファイルに適用される。
item.content = document.to_xml
item.save
べんり。
こうして、兼ねてから用意しておいたgemの組み合わせで、今回のパッチプログラムは比較的すんなり書くことができた。気持ちがいい(とは言え、今回の本に特化した方法ならもっとずっと簡単に書ける。unzip、zip、sedくらいで充分だ。明らかにオーバーエンジニアリング)。
今回足りなくて自分で書かないといけなかった汎用パーツは「EPUB CFIからNokgiri::XML::Rangeに変換する」という処理だったので、これは一般化してEPUB Parserに入れておきたい。
EPUBパッチの試み
こうして、ある程度アドホックに、ある程度一般的にEPUBのパッチプログラムを書いてみた。書いてみて一番大変だったのは、正誤表のEPUB CFIを作るところだった。
本の中から、適用対象のXHTMLファイルを探して、その中の適用箇所を探すまでは簡単だ(grepなどでできる)。でもその場所を表現するための要素の順番などを数えるのが面倒くさい。そして間違える。
あと、複数の操作を一つのプログラムで行うときの順番の扱いは、色んなケースを集めて検討する必要があると感じた。今回は正誤表を逆順に並べて適用していったけど、前の方から順番でも、そうと決まっていれば別にいい。ある処理でDOM構造が変わるとしても、「ずれた」後のDOMツリーに対してその後の操作のCFIが書かれていればいいからだ。
もう少し引いた視点で、パッチの適用対象のバージョンや順番も、取り決めを作ってみんなに周知する必要があると感じた。今回のパッチプログラムの後に正誤表が追加されたとする。すると、
- gihyo.jpからダウンロードしたファイルには、今回分と追加分がまとまったパッチを適用したい
- 今回のパッチを適用して楽しんでいたファイルには、追加分だけ適用したい
ということになる。この辺、「二つをまとめたパッチ」を作るかどうか、作るにはどういう手順で作るか、それとも必ず一つずつ順番に適用することにするか(「久し振りに開いた本」は、「パッチの適用待ち」の時間が非常に長くなるかも知れない)、決めないといけない。
また、サードパーティ製のパッチについても検討できると素晴らしい。識者による注釈や、出版社を通さない作者によるコメンタリーなど(小説へのコメンタリーは、吉野茉莉さんがやっていた)用意して配布できるといい。そうした物は「どのバージョンのパッチ適用後なら適用していいか」「それより後のパッチも適用した後だった場合、どうしたらいいのか」といった難しい検討が必要になる。
差分アップデートも同様だけど、「(本文を参照しない)CFIだけでの演算」でいろいろ解決できると便利なのだけど、そういったことはできるのだろうか……(というか、これができるかどうか見てみたいので差分アップデートをやりたいのだ)。
EPUB CFIについて思うこと
EPUB CFI、あまり好きではないのだけど、今回のようなことをやるには、順番が付くという性質が役に立った。
今回分かった難点というか、改善点になるのかな、は、『APIデザインケーススタディ』では(XHTMLの)id属性を全然使っていないこともあって、ぱっと見、どのトピックに対する操作なのか全然分からない(idがある場合はその値がCFIに現れる仕様になっている)。idに限らず、classなど色んな属性についてもCFI表現に出せるようになってるといいのかなあ。乱用される危険も出るが。
差分アップデートの仕組みに足りていない物
今回一番大変だったこととしてCFIの作成を挙げたが、そこが、差分アップデートの仕組みに足りていない。
(iBooks Authorなど)オーサリングツールで何か操作をして保存したりアイコンをタップすると、自動でパッチを書き出すようになっているとすごく便利だが、僕にはGUIは理解が追い付かない……。
別の方法としてEPUB用のdiffコマンドを作るというのがある、と言うか、目指している。旧EPUB、新EPUBを並べて差分を計算し、パッチの形で書き出してくれるツールだ。これでネックになるのはDOMツリーの差分計算だ。調べたところ「NP困難」と呼ばれる類の問題らしく、一般的に解決するのは非常に難しいらしい。でも、DOMの差分が作れると、ウェブ開発者一般にもとても役立つと思うので、何か、妥当でうまく利く制約があるといい。アルゴリズムとしてはBULDアルゴリズムというのが速いらしい。C++の実装はあるけれど、僕には敷居が高いので、これのポーティングを目的として今Goを勉強している(速い言語がいい)。仮想DOM方面から何か出てきたりしないかな。
終わりに
なんだか、実現できているのは小さなことだし、書いているコードは少ないのに、長く話してしまった。お恥ずかしい。
最後に大事なことを一つ、たださんと同じく声を大にしてこう言いたい。
ともあれ、こんなことができるのも、ちゃんと正誤表を公表してくれる著者と、DRMをかけない素のEPUBファイルを配信してくれる出版社があればこそ。感謝したい。
追記
なんか間違えてた。上で何度か「差分アップデートをやりたい」と言っているが、差分アップデートは、正に今回やったこれだ(パッチ作成の部分は今は人間がやってるのでそこは将来の話ではある)。やりたいけど遠いのは、「EPUBの差分アップデート時に、ブックマークやハイライト、メモ書きなども同時にアップデートする(EPUBアップデートによって場所が動いても追従する)」ということだった。